
Machine Learning im Kontext herkömmlicher Schätzverfahren
Künstliche Intelligenz verspricht im Kontext der Immobilienbewertung wie auch der Immobilienpreisbeobachtung und -Prognose ein hohes Potenzial. Alle reden über die “neuen” Methoden aber zuweilen erhält man den Eindruck, dass die ernsthafte Auseinandersetzung mit dem Thema zu sehr in den Hintergrund rückt.
Daher haben wir Einblick in unsere aktuelle Forschung anhand einer Case-Study auf dem Arbeitskreis Immobilienpreise des BBSR gewährt und kurz zum Thema vorgetragen. Es ging uns insbesondere darum, eine Diskussion zu den Potenzialen und Fallstricken der aktuellen Entwicklungen anzustoßen.
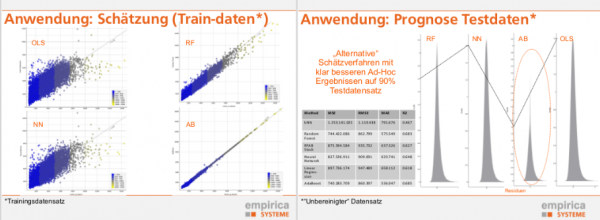
Am Beispiel des Berliner Wohnungsmarktes haben wir lineare Regression (OLS), Random Forest, Neuronales Netz, AdaBoost und KNN miteinander verglichen und diskutiert. Wie zu erwarten haben insbesondere Random Forest und AdaBoost deutlich bessere Prognosequalitäten als eine herkömmliche Regression. Besonders zum Tragen kommen die Vorteile, wenn man größere Trainingsdatensätze hinzuzieht, was bei herkömmlichen Verfahren ja keine Effekte haben darf – es sei denn, das Modell ist schlecht bzw. falsch.
Dennoch gibt es auch Diskussionspunkte: Der Vorteil eines größeren Daten- bzw. Variableninput führt einerseits zu unübersichtlichen Schätzungen – mit Folgen für die geforderte Modelltransparenz und andererseits zu einer hohen Anforderung an die Dateneingabe durch Gutachter. Weitere Informationen zum Thema und dem Arbeitskreis Immobilienpreise beim BBSR finden Sie hier.